
Om maar met de deur in huis te vallen: de meeste experimenten zullen niet-significante uitkomsten hebben. Zelfs als je goed hebt gekeken naar je MDE, een goede data-set hebt en alle basics kent.
Volgens de gegevens van Experiment Engine zijn 50% tot 80% van de testresultaten niet-significant. VWO en Convert.com hebben schattingen gemaakt waaruit blijkt dat slechts ongeveer 1 op de 7 A/B-tests een winnende test is.
De afbeelding hieronder illustreert de hypothetische verdeling van het rendement op investering voor ideeën die door een bedrijf zijn gegenereerd (Online Experimentation: Benefits, Operational and Methodological Challenges, and Scaling Guide, Iavor Bojinov en Somit Gupta, 2022)
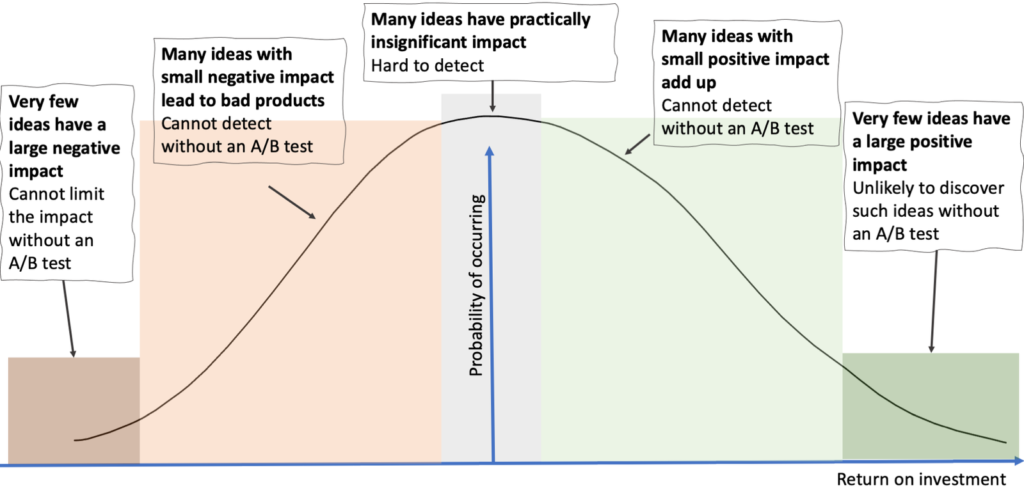
Aangezien niet-overtuigende resultaten eerder de norm dan de uitzondering zijn, wat kun je doen als je ze hebt?
Wat je kunt doen als je een non-significante testuitslag hebt:
- Allereerst kan het zijn dat je test voor non-inferioriteit: je hoopt dat je verandering geen impact heeft, dan voor je natuurlijk je test door.
- Naast dat je je test afrekent op je hoofdkpi, heb je misschien ook enkele ondersteunde metrics. Vertellen die je iets? Idealiter heb je deze ondersteunende doelen eerder bepaald. In het geval van het verhogen van conversie voor eCommerce is je hoofddoel vaak transacties of verkopen en een ondersteunend doel daaraan is add to carts of CTR naar je checkout.
- Als je test zowel op mobiel als desktop heeft gelopen is het altijd goed om te kijken of er grote verschillen tussen deze apparaten zijn. Pas wel op voor ‘data marteling’. Soms worden conversiespecialisten of data analisten door managers of stakeholders in de richting van data marteling (data torture) geduwd. Er kunnen vragen gesteld worden als: ‘En heb je dit wel gemeten? En dit? En dit? Er moet toch ergens een winnaar zijn?’ En ja: als je je data maar vaak genoeg opknipt in categorieën of diep genoeg graaft dan is er altijd wel een winnaar te vinden. Maar: dat resultaat is waarschijnlijk niet in de buurt van je originele metrics en wat je wilde meten. Vaak is het een afleiding, om onszelf gerust te kunnen stellen dat we ‘iets’ gevonden hebben.
- Ben je bang dat een andere test jouw A/B-test beïnvloed heeft? Segmenteer deze data dan uit je test.
- Soms kun je kwalitatieve data verzamelen (zoals een hotjar/usabilla poll) in de variant van je test, of je kunt kijken naar gebruikersopnames of heatmaps, leer je daar nog wat uit?
Te veel niet-significante uitkomsten, wat kan je doen?
Als je twijfelt aan het aantal experimenten dat een niet-significante uitkomst heeft, verbeter dan je proces:
- Verzamel je genoeg data en heb je een representatieve data sample? Dit kun je checken met de Speero Calculator. Kijk vooral naar het Minimal Detectable Effect. Dat is het effect dat je met je data set kan meten. Een ‘gezonde’ MDE ligt < 15%. En als richtlijn kun je denken aan kleine copy tweaks, daarvoor heb je veel traffic en zo’n 1 – 3% MDE nodig, grotere wijzingen die veel impact kunnen hebben kun je schatten op een MDE van 1 – 10%. En innovatie, disruptieve ideeën kunnen misschien een grotere impact halen.
- Zat je hypothesis goed in elkaar? Check deze Hypothesis Kit.
- Welk data-punt had je gebruikt om je hypothesis te ondersteunen, of kwam het idee voor de test als een mening of aanname van iemand? Check of je onderzoek en de data waaruit je A/B-test is voortgekomen niet verkeerd geïnterpreteerd is, of de situatie inmiddels veranderd is (heb je alleen tijdens black friday data verzameld, dan is deze data natuurlijk heel anders dan reguliere data). Of heb je misschien de input verkeerd ingeschat?
- Kan er op een andere manier gevalideerd worden? Denk aan User Testen, Copy Testing, 5 Second Testing.
- Was de wijziging die je maakte niet te klein voor de MDE (Minimum Detectable Effect)? Moet je idee of hypothese misschien op meerdere plekken op de pagina uitvoeren of je idee groter maken?
- Is de test afgevuurd op de juiste bezoekers? Als jouw verandering beneden op de pagina was, zorg er dan voor dat de test alleen wordt afgevuurd op bezoekers die op dat punt op je website komen (dit kun je bijvoorbeeld doen op basis van scroll percentage)
Wanneer verbeter en herhaal je je test?
Soms is een verandering niet groot of gewaagd genoeg (voor de dataset – MDE). Misschien wil je je verandering groter maken of de test in een andere richting proberen. Uiteindelijk helpt prioritering hierbij. Als je een nieuw idee hebt na een niet-significante test, dan helpt een priotizeringsmodel zoals PXL met bepalen of je hier gelijk mee aan de slag moet, of dat andere ideeën meer potentie hebben.
De filosofie van het accepteren van niet-significante resultaten
Laat me je iets persoonlijks vertellen: ik dacht dat veel van mijn ideeën, aanpassingen of testen een significante impact zouden hebben. Maar nu ik 500+ experimenten heb gedaan, weet ik beter. De meeste uitvoeringen van ideeën hebben slechts een klein effect op bezoekers, een effect dat vaak niet gemeten kan worden.
Dit leerde me iets over hoe we als mensen het effect van onze ideeën, meningen en aanpassingen overschatten. De meeste veranderingen doen er helemaal niet zoveel toe. Het deed me denken aan Illusory Superiority (een persoon overschat zijn of haar eigen kwaliteiten), maar ook het IKEA-effect (hoe meer tijd je besteed aan het opzetten van iets, of het bedenken van een idee, hoe meer je ervan houdt).
Veel beslissingen concludeerde ik, voor A/B-testen, in het bedrijfsleven of in je persoonlijk leven hebben helemaal niet zo’n groot effect. Het is misschien 1 op de 7 ideeën die je echt van je schoenen blaast. En dankzij A/B-testen: kun je die 1 op de 7 vinden.
Hulp nodig 👇?

✅ Of volg me op Linkedin om op de hoogte te blijven.